Zeitreihenanalyse (Time Series Analytics)
Das Time Series Analytics Paket für die ANKHOR FlowSheet Daten-Werkbank (Workstation Edition) ist speziell für die Verarbeitung von Zeit basierten Daten entwickelt worden. Die Bibliotheken dieses Pakets beinhalten Operatoren zur direkten Verarbeitung, Filterung, Analyse und Visualisierung von Zeitreihendaten. Leistungsfähige Assistenten-Operatoren und eine speziell auf diesen Datentyp abgestimmte Dateninspektion erleichtern Ihnen die Modellierung, insbesondere bei einer großen Anzahl von Datenquellen und daraus resultierender Datenmenge.
Zeit basierte Daten treten in vielen Bereichen auf, seien es Messwerte im Labor, Produktionsdaten oder Energieverbrauchsmessungen im industriellen Umfeld. Eine Analyse dieser Daten mit klassischen Datenbankansätzen leidet aber unter mehreren Problemen:
- Häufig werden für einzelne Analysen sehr viele, schwer indizierbare Daten benötigt. Die Datenbank muss also für die meisten Anfragen über den kompletten Bestand an Messdaten iterieren, um ein Ergebnis zu produzieren.
- Es kommen leicht hunderte Millionen bis Milliarden Messwerte zusammen, die nicht in Alternativen wie Spreadsheets bearbeitet werden können.
- Die Daten werden nicht immer im festen Zeitraster erhoben. Das Raster kann von Millisekunden bis Tagen schwanken, oder sogar auf zufälligen Zeitpunkten basieren, was eine Verknüpfung von mehreren Messungen erschwert.
- Die Anzahl und Art der Messungen kann während der Nutzung der Daten stark schwanken, so dass ein Datenbankschema verwendet werden muss, dass die einzelnen Messungen verschiedener Sensoren vertikal in einer einzelnen Tabelle kombiniert.
- Aggregate müssen über variable Intervalle/Gruppen erstellt werden, die nur schwer in klassische Datenbanksprachen zu formulieren sind.
- Häufig werden Abhängigkeiten zwischen einzelnen konsekutiven Messwerten benötigt (z.B. für Änderungsanalysen oder Interpolationen), die nur recht problematisch über Self-Joins erreicht werden können.
Übliche Lösungen, wie feste künstliche Raster oder sehr viele vorberechnete Teilsequenzen lösen das Problem nicht wirklich und verkomplizieren eine Erweiterung der Anwendung.
ANKHOR FlowSheets in Memory Architektur erlaubt zusammen mit seiner flexiblen Art der Datenverarbeitung einen alternativen Ansatz. Die Daten werden in ihrem originalen Raster gespeichert, es findet auch keine Vorverarbeitung statt, die eine spätere Änderung der Auswertung erschweren oder verhindern würde.
Lösungsbeispiel mit Energie- und Produktionsdaten:
In diesem Lösungsbeispiel werden Energie- und Produktionsdaten einer simulieren Produktionslinie untersucht. Übliche Produktionsdaten umfassen numerische Werte, wie z.B. Verbrauchs- oder Lastgrößen, kategorische Daten wie Maschinenzustände oder freie Zeichenketten wie z.B. Produkt- oder Kundeninformationen für aktuelle Abläufe.

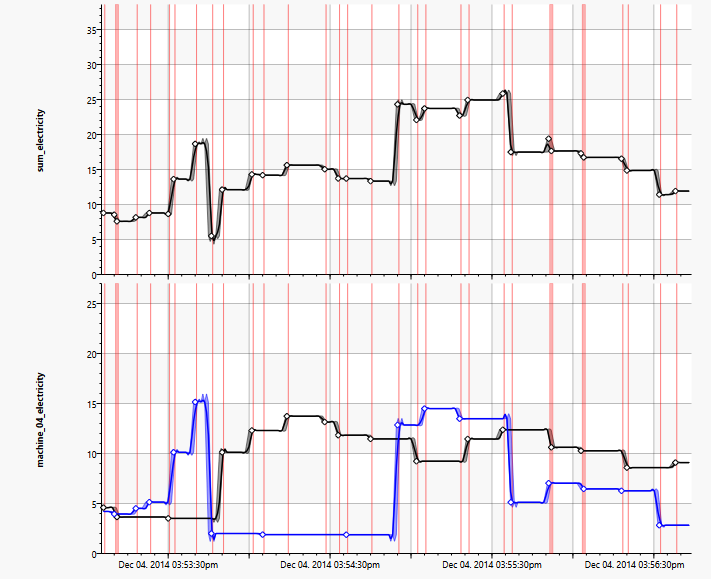
Im Schaubild links werden im unteren Abschnitt die Stromverbrauchskurven zweier Maschinen gezeigt, im oberen die Summe der beiden Kurven.
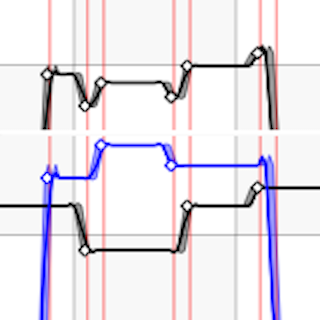
Betrachtet man ein kürzeres Intervall, erkennt man die einzelnen Messwerte:
Die Summenkurve (oberes Diagramm) hat überall da automatisch berechnete Werte, wo mindestens eine der beiden Ausgangskurven einen Messwert hatte. Es gehen also bei einer Bearbeitung keine Messwerte verloren, in dem ein künstliches Raster verwendet würde.
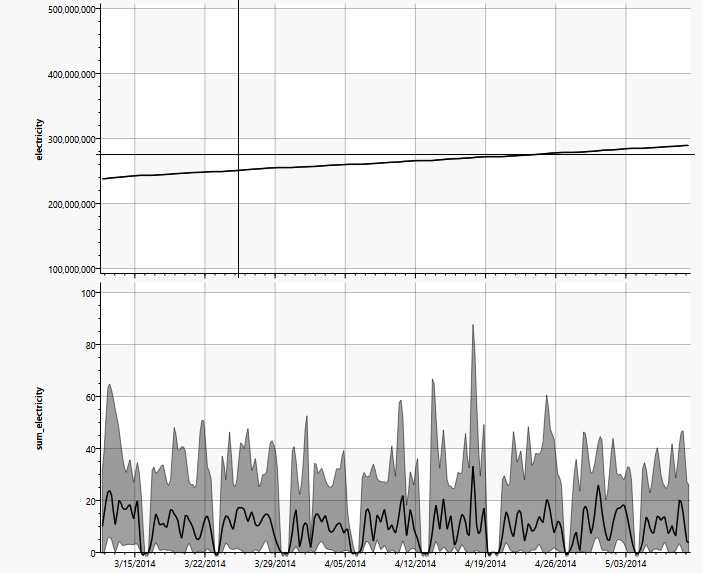
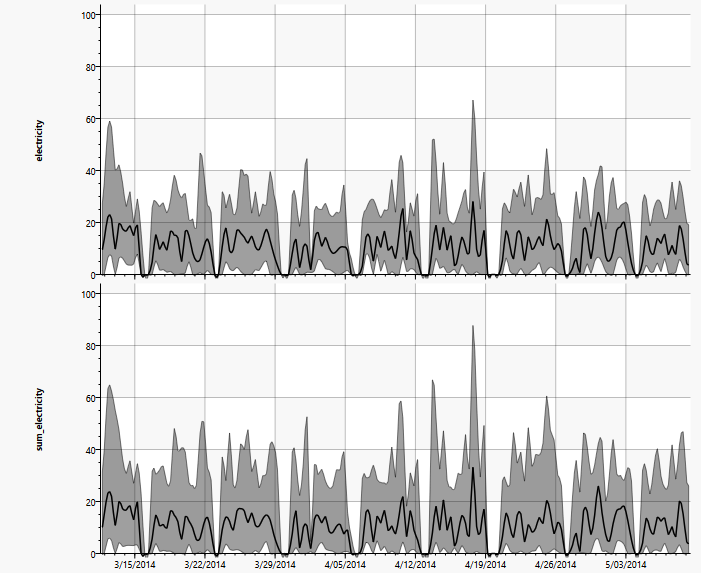
Auch zeitliche Abhängigkeiten innerhalb einer Messkurve können problemlos bearbeitet werden, wie das nächste Beispiel zeigt. Der Energieverbrauch einzelner Maschinen wird als aktueller Wert, der Gesamtverbrauch aber kumulativ als Zählerstand (oberes Diagramm) gespeichert:
Dies erschwert einen Vergleich mit den kumulierten Daten der einzelnen Maschinen. Wird die Ableitung der Messung verwendet (bzw. der Differenzenquotient), wird die Abhängigkeit sofort deutlich.
Die gegenteilige Operation, also die Integration des aktuellen Verbrauchs ist ebenfalls problemlos möglich:
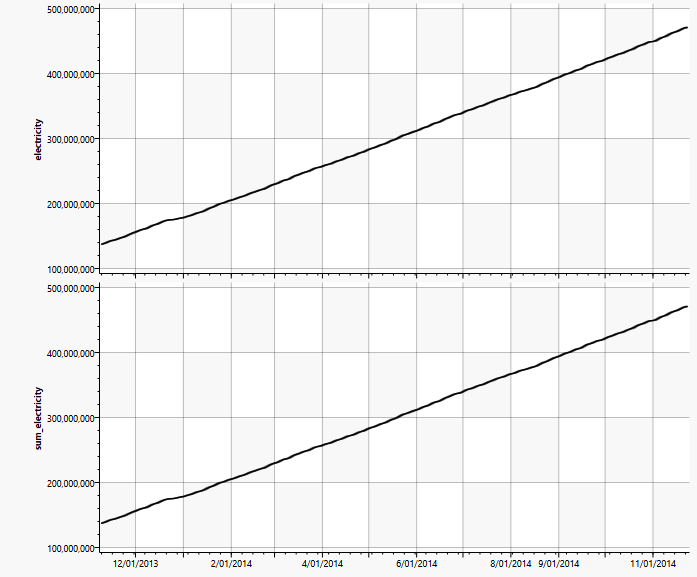
Die Kombination aus Ableitung und Integration kann auch genutzt werden, um wechselnde Energiekosten im Tagesablauf zu berücksichtigen. Da sich die Kosten nach dem aktuellen Verbrauch und der Uhrzeit berechnen, aber lediglich der aktuelle akkumulierte Zählerstand gespeichert ist, muss dieser differenziert werden, um auf den aktuellen Verbrauch zu kommen. Dieser kann dann mit den Kosten pro Einheit verrechnet und schließlich wieder integriert werden, um auf die akkumulierten Kosten zu gelangen.
Im folgenden Diagramm wird dies in Einzelschritten gezeigt. Aus der ursprünglichen kumulierten Energiekurve „elerctricity“ wird sowohl die aktuelle Uhrzeit „hour“ als auch der aktuelle Verbrauch „deltae“ gewonnen. Die Uhrzeit wird mit einer Tabelle zu den Energiekosten zu einer „cost“ Funktion kombiniert, die dann mit dem aktuellen Verbrauch zu einer aktuellen Kostenkurve „deltac“ multipliziert wird. Das Integral davon „total“ liefert entsprechend die akkumulierten Energiekosten.
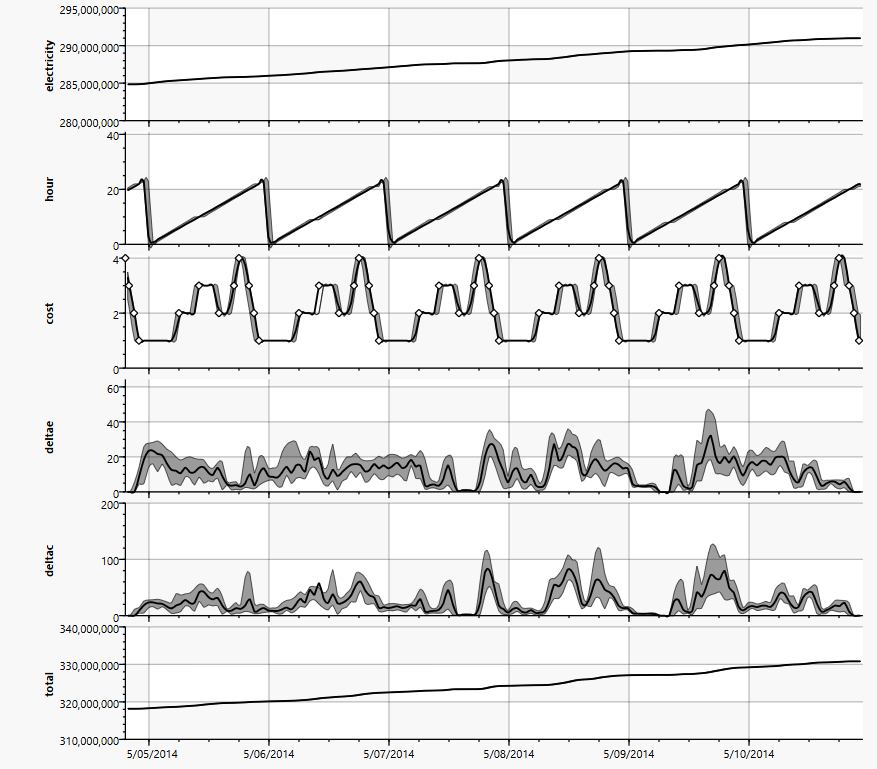
Der dazugehörige Operator-Graph zeigt die grundlegende Arbeitsweise mit Zeitreihen:
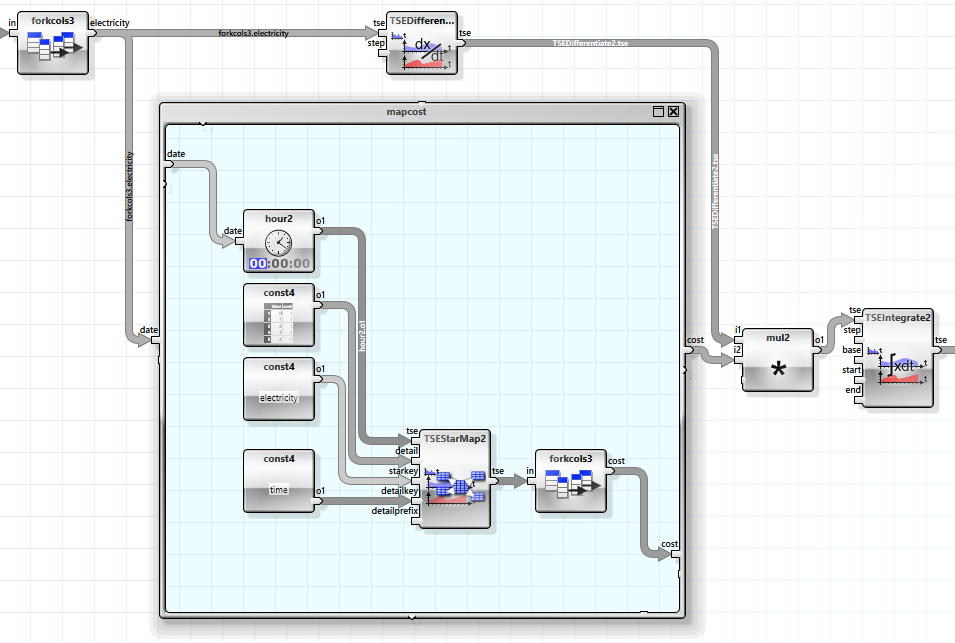
Die einzelnen Zeitreihen in einem Satz werden wie Spalten einer Tabelle verarbeitet, entsprechend wird der Operator zum Abzweigen einer Spalte „forkcols“ oben links verwendet, um die Messreihe für den gesamten Stromverbrauch zu extrahieren. Der eingebettete „mapcost“ Operator Graph enthält die Operatoren zur Abbildung der Uhrzeit in die Stromkosten.
Viele Fragen lassen sich bereits recht einfach mit dem „TSEAggregateView“ Wizard beantworten.
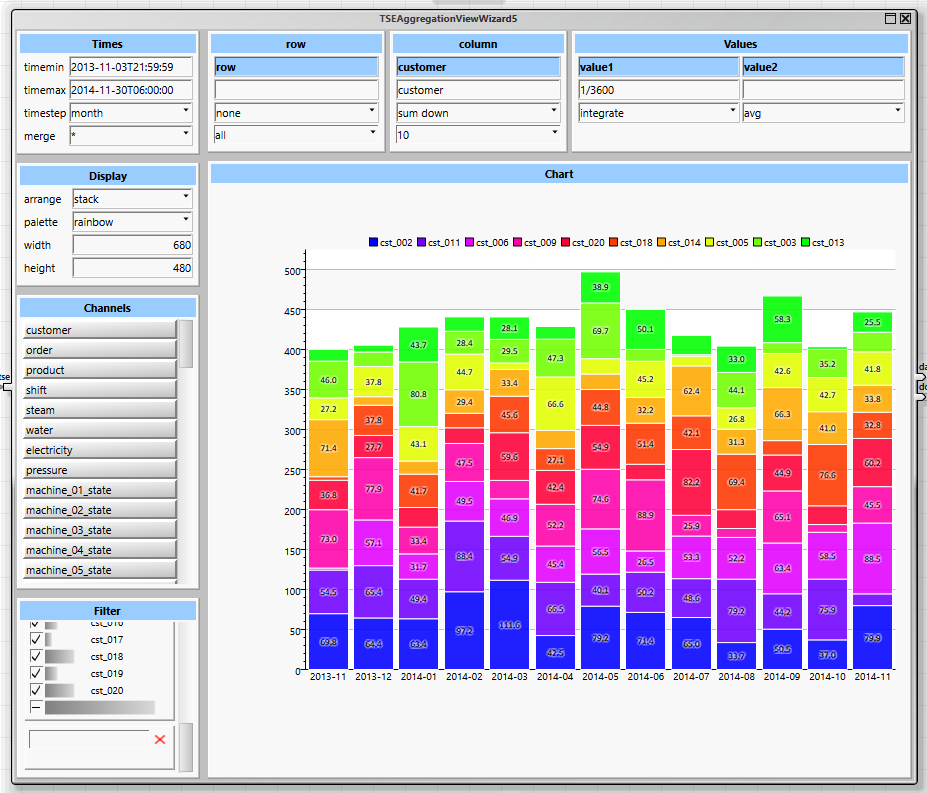
Mit diesem Wizard können unterschiedliche Größen über verschiedene Zeitabstände aggregiert und gruppiert werden. Ein zusätzlicher Filter kann die Darstellung oder die Berechnung verändern. Beispiele finden Sie in den folgenden Diagrammen:
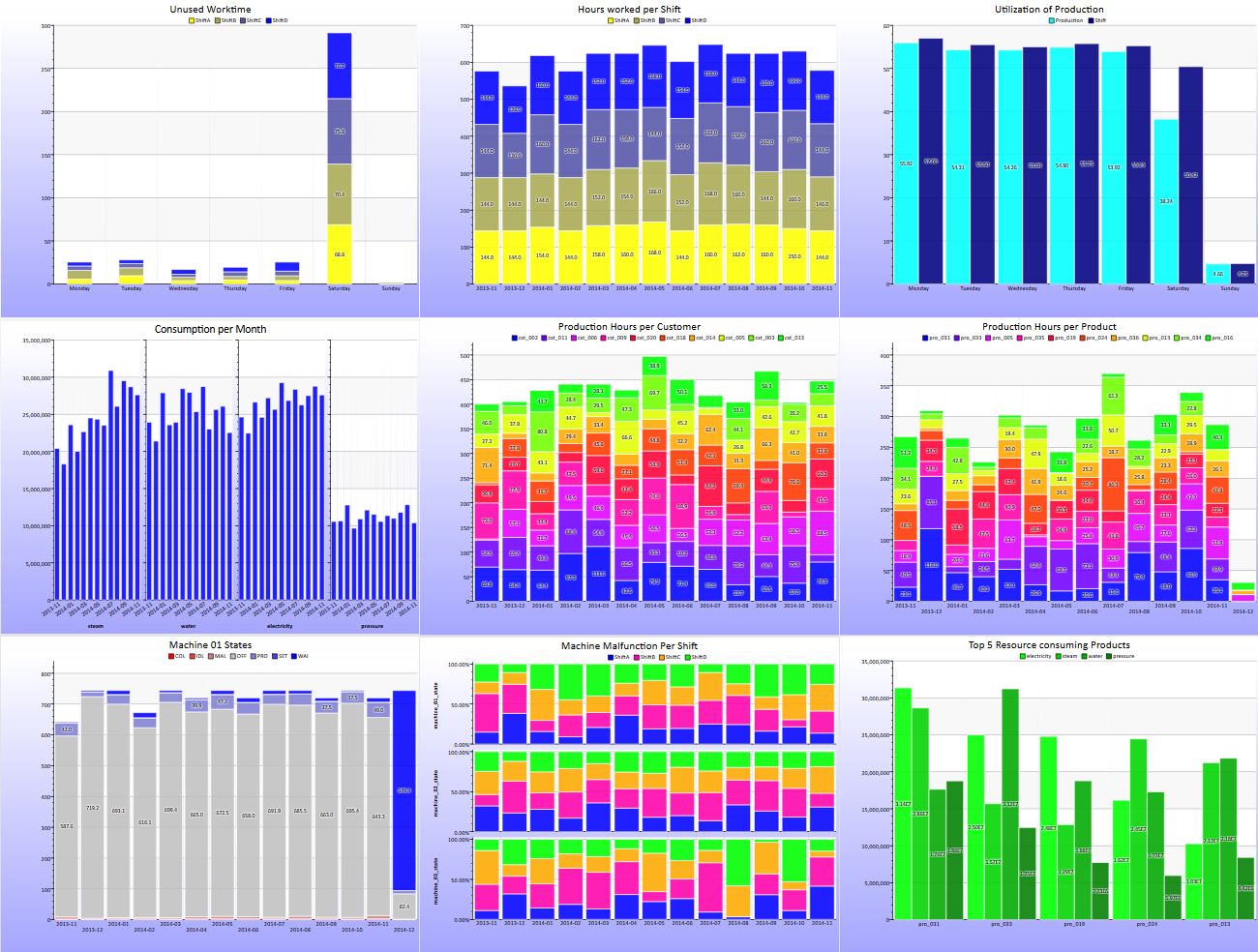
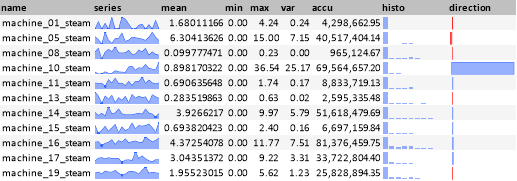
Im Weiteren sollen nun einige spezifische Fragestellung beantwortet werden. Als erstes die Frage, ob sich der Energieverbrauch im Laufe des Beobachtungszeitraumes verändert hat, und wenn ja warum. Dazu betrachtet man zuerst eine Übersicht über den Verbrauch insgesamt.
Deutlich ist an der „direction“ Anzeige zu erkennen, dass der Dampf Verbrauch im Vergleich zu den drei anderen Größen eine deutliche Tendenz nach oben besteht.

Die Ursache kann eingekreist werden, wenn man den Dampfverbrauch der einzelnen Maschinen genauer betrachtet:
Maschine 10 sticht deutlich heraus. Um nur eine höhere Auslastung auszuschließen, werden nun die anderen Energiedaten der Maschine mit beobachtet:
Deutlich erkennbar, ist nur der Dampfverbrauch angestiegen, was eventuell auf eine sich stetig vergrößernde Undichtigkeit hindeutet.

Um dies nun noch im Detail untersuchen zu können, werden zwei Produktionsabläufe gesucht, bei denen Maschine 10 involviert ist. Mit dem „TSEAggregateView“ Wizard, ist leicht zu bestimmen, welche Produkte besonders viel Dampf bei Maschine 10 benötigen.

Produkt 13 bietet sich an. Um zwei günstige Produktionszeiträume zu finden, wird es als Markierung im „TSEZoomView“ Wizard genutzt.
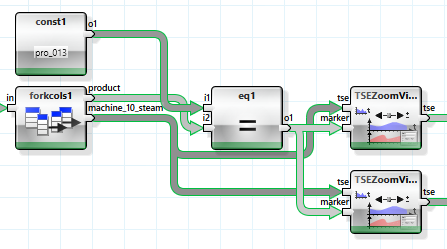
Die markierten Bereiche lassen sich so leicht finden, und entsprechende Intervalle selektieren.
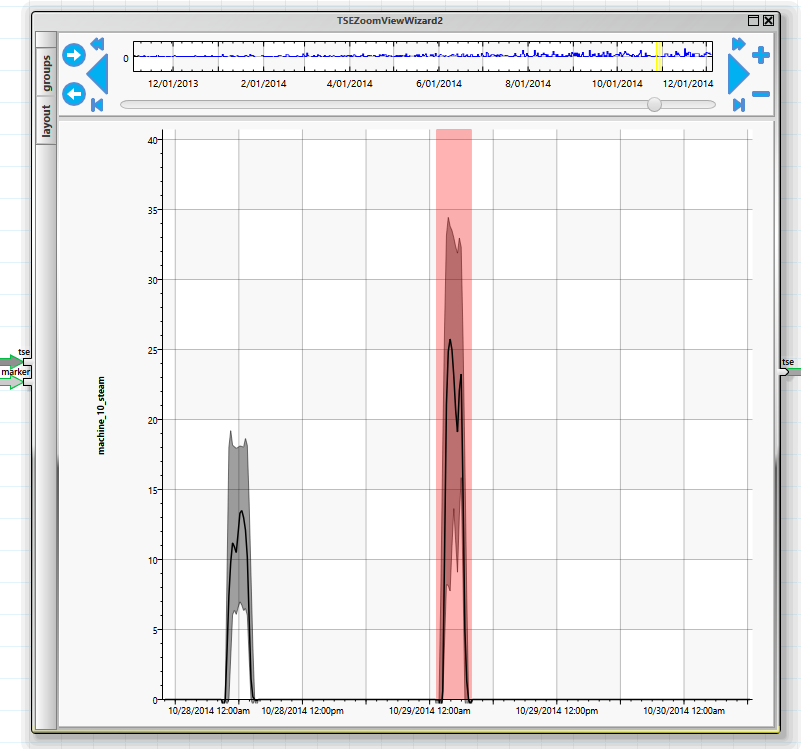
Die beiden Intervalle können dann in einen gemeinsamen Zeitraum verschoben und zusammengefügt werden.
Der „TSEMultiScope“ Wizard erlaubt dann ein einfaches Vergleichen der Produktionskurven:
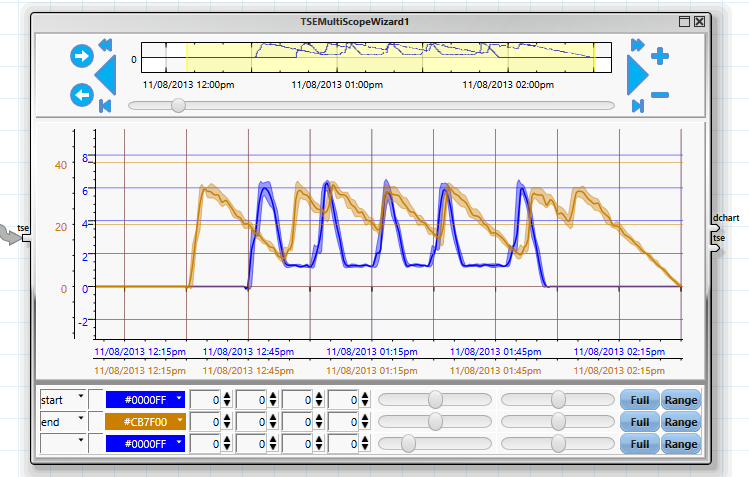
In beiden Zeiträumen liegt der Verbrauch im inaktiven Zustand bei 0, das Leck befindet sich also eher innerhalb des aktiven Bereiches der Maschine. Deutlich zu erkennen ist, dass der Verbrauch im späteren Intervall fast fünfmal höher ist als im früheren, die Produktionsgeschwindigkeit aber etwa unverändert bleibt.
Die Produktion wird in einem Vier Schicht System gefahren, was in folgendem Diagramm zu ersehen ist.
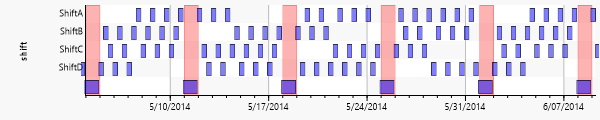
Da die Zusammensetzung der Mitarbeiter pro Schicht als stabil angenommen wird, kann anhand der Leistung pro Schicht auf einen möglichen Fortbildungsbedarf für Mitarbeiter dieser Schichten geschlossen werden. In den folgenden drei Diagrammen wird klar, dass die Mitarbeiter von Schicht „C“ sowohl deutlich weniger Energie verbrauchen, als auch weniger Störungszeiten vermelden müssen.
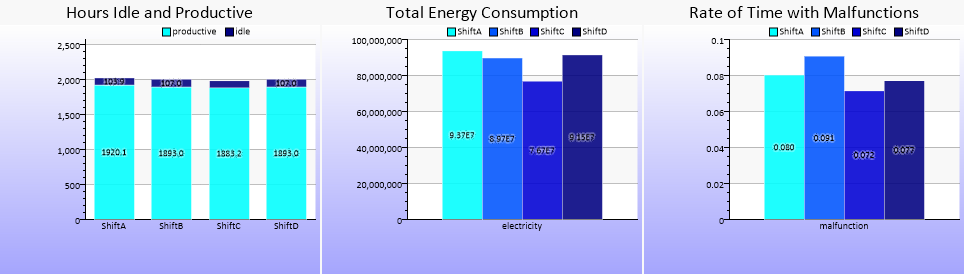
Die tatsächliche Produktionsdauer ist bei allen vier Schichten fast identisch. Die erhöhte Störungsrate von Schicht „B“ lässt auf einen zusätzlichen Trainingsbedarf schließen. Die kombinierte Störungsdauer aller Maschinen wurde mit folgendem Graph berechnet.
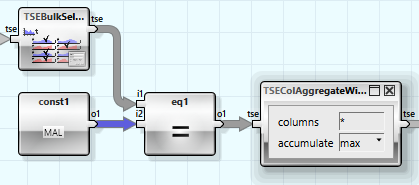 Der „TSEBulkSelect“ Wizard wählt die Maschinenzustände aller Maschinen aus, die danach mit dem Störungszustand „MAL“ verglichen werden. Danach werden diese kombiniert.
Der „TSEBulkSelect“ Wizard wählt die Maschinenzustände aller Maschinen aus, die danach mit dem Störungszustand „MAL“ verglichen werden. Danach werden diese kombiniert.
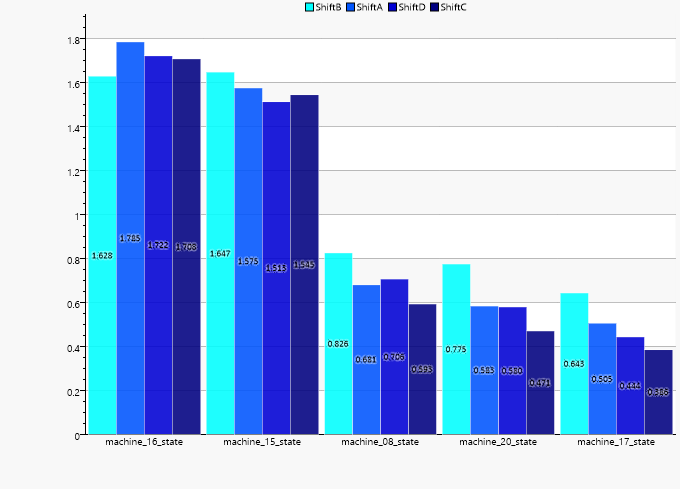 Im folgenden Diagramm wird nun noch die Störungsdichte nach Schicht und Maschine aufgeschlüsselt, so dass deutlich wird, welche Maschinen insgesamt und im Besonderen für Schicht „B“ ein Problem darstellen.
Im folgenden Diagramm wird nun noch die Störungsdichte nach Schicht und Maschine aufgeschlüsselt, so dass deutlich wird, welche Maschinen insgesamt und im Besonderen für Schicht „B“ ein Problem darstellen.
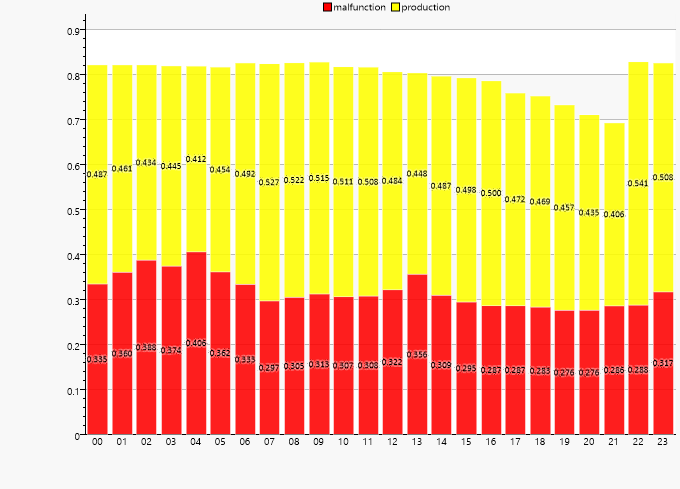 Hier stellt sich die Frage, wie viel Zeit des Produktionsablaufs durch Störungen behindert werden. Im folgenden Diagramm wird das auf die Stunden des Tages abgebildet:
Hier stellt sich die Frage, wie viel Zeit des Produktionsablaufs durch Störungen behindert werden. Im folgenden Diagramm wird das auf die Stunden des Tages abgebildet:
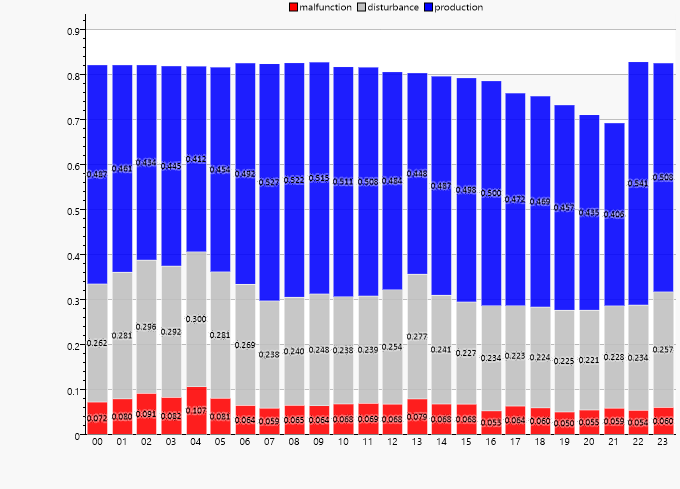 Deutlich erkennbar ist eine Häufung in den frühen Morgenstunden. Da kurze Störungen keine oder nur geringe Auswirkungen auf den Betriebsablauf haben, sollen nun noch Störungen über 10 Minuten getrennt angezeigt werden.
Deutlich erkennbar ist eine Häufung in den frühen Morgenstunden. Da kurze Störungen keine oder nur geringe Auswirkungen auf den Betriebsablauf haben, sollen nun noch Störungen über 10 Minuten getrennt angezeigt werden.
Hierzu wurde der Operatorgraph zur Bestimmung einer Störung entsprechend um eine zweite Zeitreihe ergänzt, in der alle Störungen unter 10 Minuten entfernt wurden.
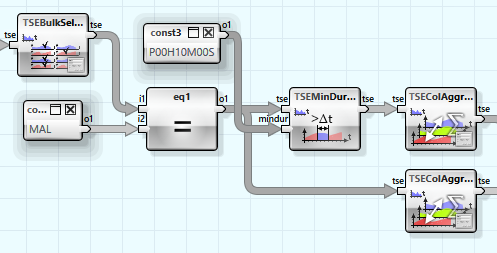
Als nächstes soll nun genauer auf den Energieverbrauch nach Produkt eingegangen werden. Da in den Zeitreihen lediglich Produkt und Ordernummer, nicht aber die Ordergröße festgehalten wurde, müssen die Zeitreihendaten mit anderen Produktionsdaten verknüpft werden. Diese liegen in einer CSV Datei vor.
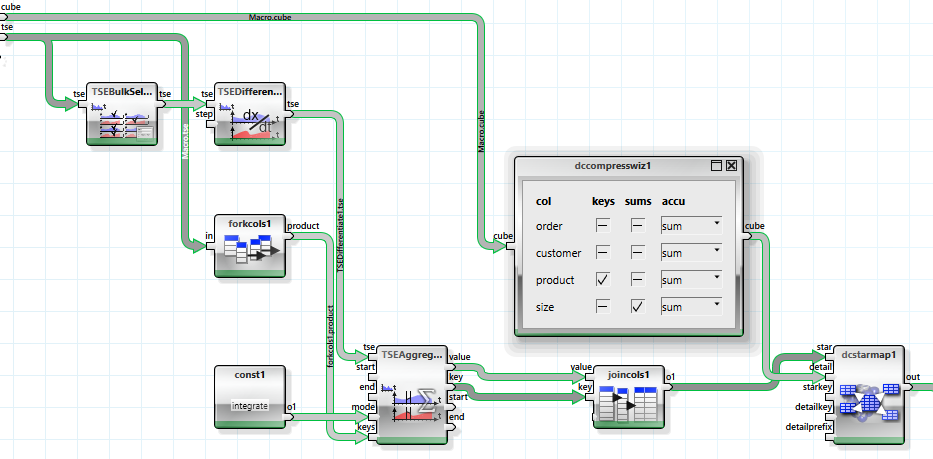
Die akkumulierten Energiedaten werden abgeleitet und dann gruppiert nach Produkten integriert. Die Ergebnistabelle wird dann mit den aggregierten Produktionszahlen verbunden.
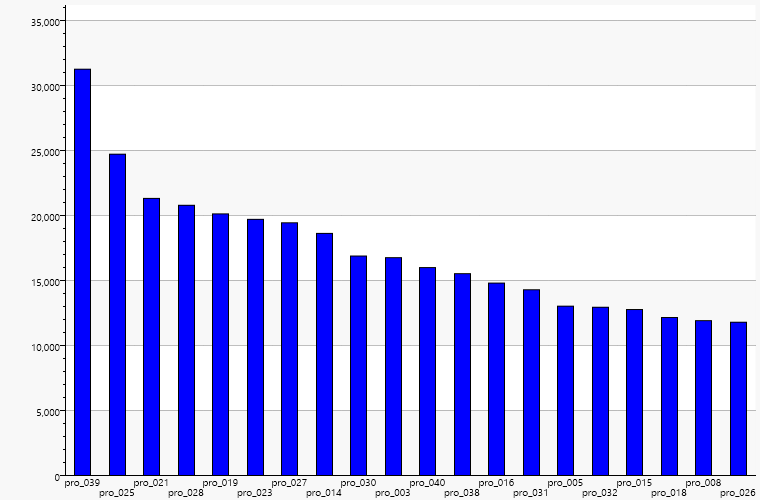 Im folgenden Diagramm wird dann der gesamte Energieverbrauch für ein Produkt geteilt durch die Anzahl der Produkte dargestellt.
Im folgenden Diagramm wird dann der gesamte Energieverbrauch für ein Produkt geteilt durch die Anzahl der Produkte dargestellt.
Im nächsten Diagramm wird noch etwas detaillierter dargestellt, wie sich der Energieverbrauch mit Produktart und Chargengröße verändert.
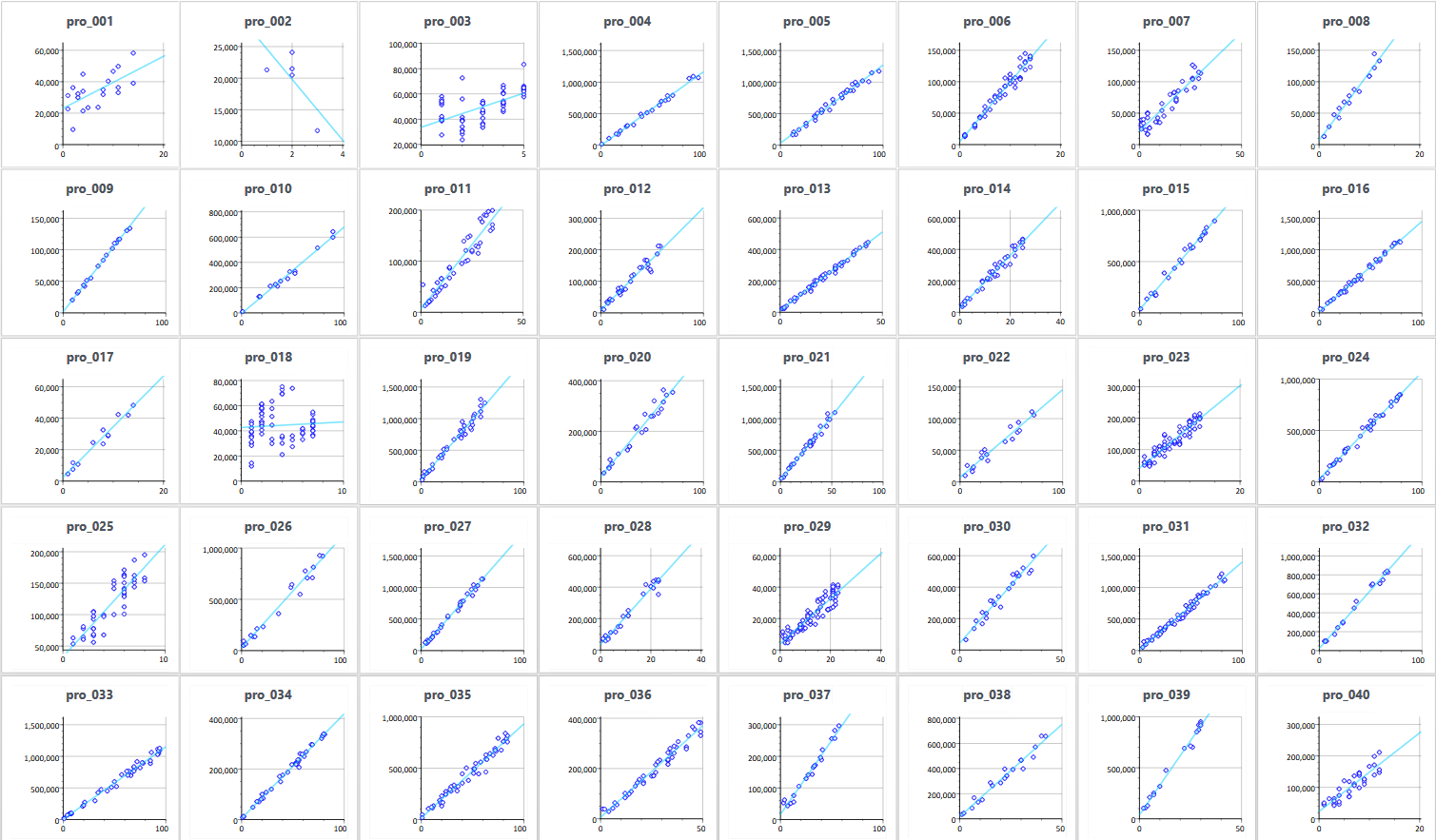
Bei einigen Produkten startet die Trendlinie eindeutig über dem Nullpunkt, so dass von einem erhöhten Einrichtungsbedarf ausgegangen werden kann. Interessant sind aber besonders die Kurven, bei denen die Streuung sehr hoch ist. Hierzu soll nun beispielhaft Produkt 3 untersucht werden. Es werden zwei Produktionsabläufe für jeweils 2 Stücke auf Maschine 1 verglichen:
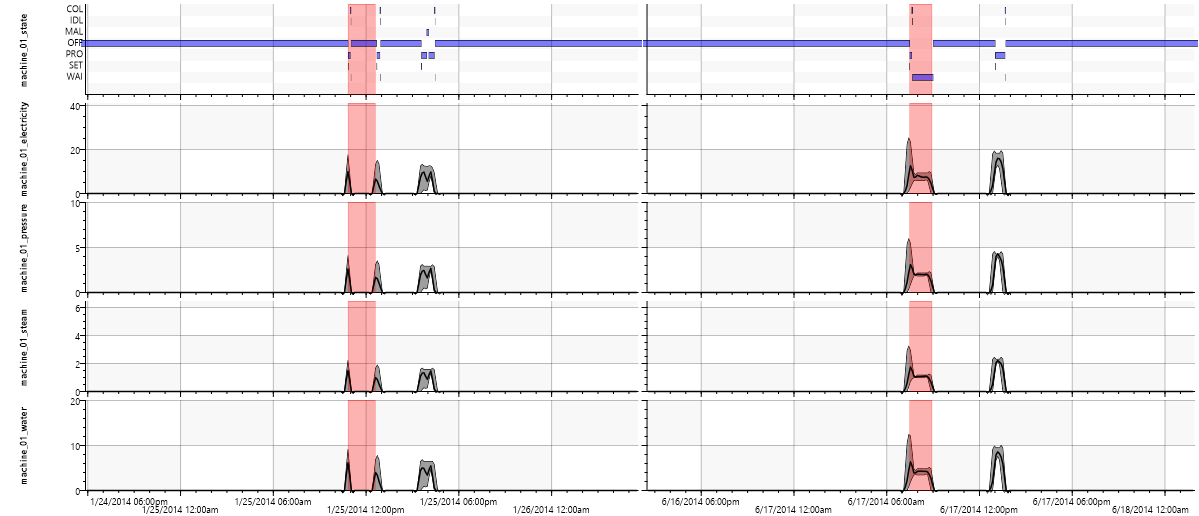
Der Energieverbrauch beim rechten Produktionsablauf ist deutlich höher, da die Maschine nach Abschluss ihrer Tätigkeit nicht abgeschaltet wird („OFF“), sondern in Bereitschaft bleibt („WAI“), bis alle anderen Maschinen der Produktionsstrecke ebenfalls fertig sind.
 Als letztes Beispiel soll noch eine Erweiterung des Maschinenparks auf Verträglichkeit mit der bestehenden Elektroinstallation untersucht werden. Die 20 Maschinen werden von 4 Stromverteilern (Grid 1 – 4) versorgt. Die erste Frage wäre also, auf welchen Verteiler die neue Maschine gelegt werden soll. Hierzu wird der Stromverbrauch der Maschinen pro Grid akkumuliert. Der Aufbau sei hierbei in einer Tabelle hinterlegt.
Als letztes Beispiel soll noch eine Erweiterung des Maschinenparks auf Verträglichkeit mit der bestehenden Elektroinstallation untersucht werden. Die 20 Maschinen werden von 4 Stromverteilern (Grid 1 – 4) versorgt. Die erste Frage wäre also, auf welchen Verteiler die neue Maschine gelegt werden soll. Hierzu wird der Stromverbrauch der Maschinen pro Grid akkumuliert. Der Aufbau sei hierbei in einer Tabelle hinterlegt.
Mit dieser Tabelle können nun die einzelnen Verbraucher zusammengefasst werden.
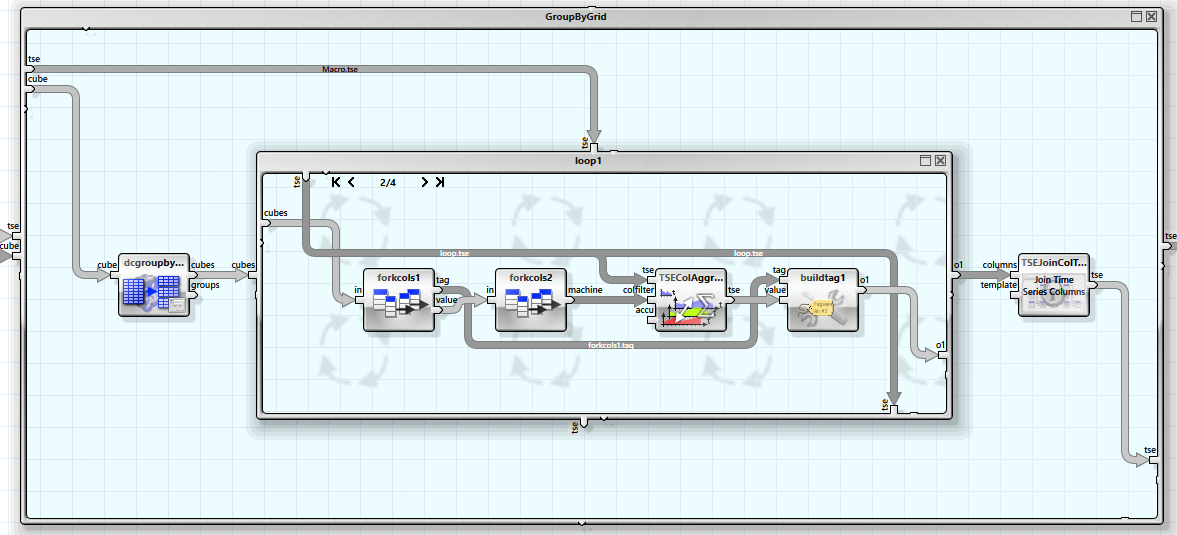
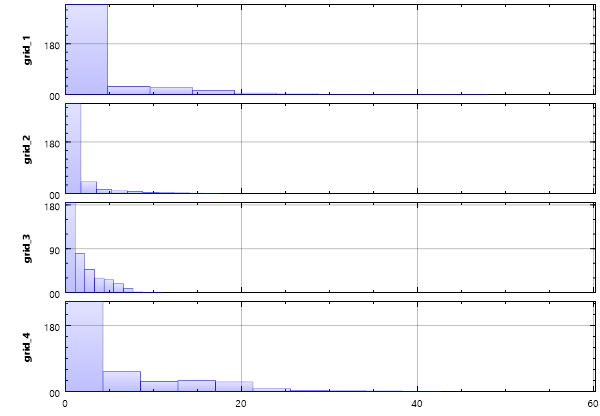 Zuerst wird die Tabelle nach dem Verteiler gruppiert, danach in einer Schleife jeweils die zugehörigen Verbraucher akkumuliert, und das Ergebnis in einer neuen Zeitreihe kombiniert. Das Verbrauchshistogramm dieser Reihe zeigt, das vor allem Verteiler 2 noch Kapazität hat.
Zuerst wird die Tabelle nach dem Verteiler gruppiert, danach in einer Schleife jeweils die zugehörigen Verbraucher akkumuliert, und das Ergebnis in einer neuen Zeitreihe kombiniert. Das Verbrauchshistogramm dieser Reihe zeigt, das vor allem Verteiler 2 noch Kapazität hat.
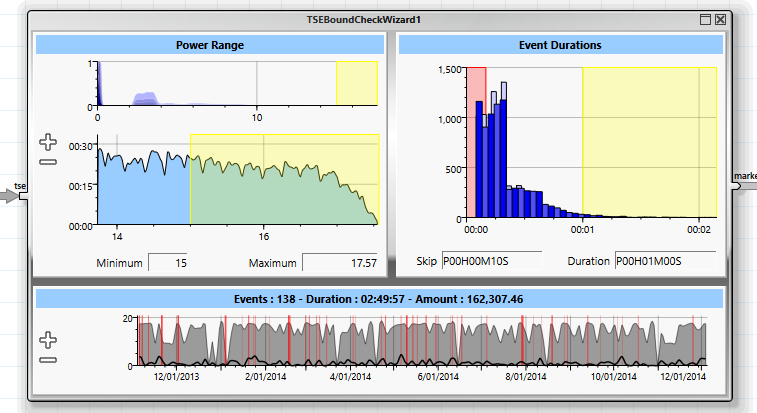 Der „TSEBoundCheck“ Wizard hilft mögliche Spitzen zu erkennen, die einen gemeinsamen Anschluss verhindern würden.
Der „TSEBoundCheck“ Wizard hilft mögliche Spitzen zu erkennen, die einen gemeinsamen Anschluss verhindern würden.
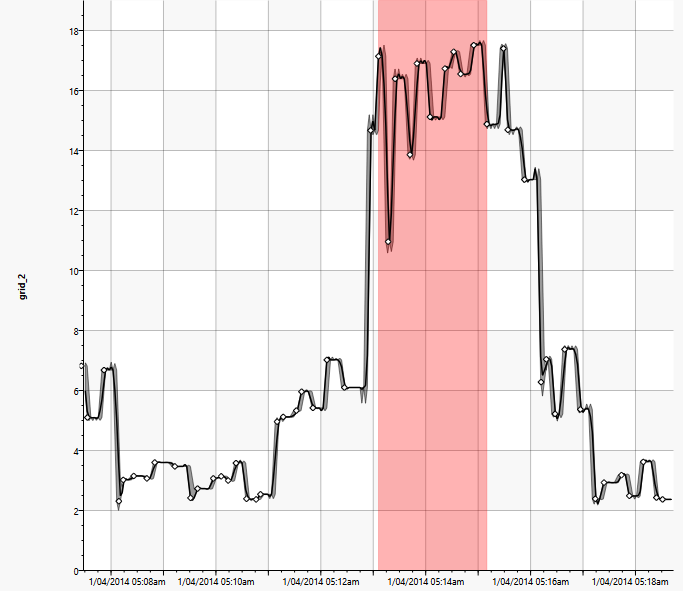
Hier wird überprüft, ob ein Spitzenverbrauch von mehr als 15kW für länger als 1 Minute anliegen kann wobei Intervalle kleiner als 10 Sekunden, in denen der Verbrauch unter der Grenze liegt nicht berücksichtigt werden. Im Histogramm auf der rechten Seite ist zu erkennen, dass diese Spitzen auftreten. Ein genaueres Histogramm über die Zeitdauer zeigt, dass auch wenige Fälle mit über 2 Minuten auftreten.

Einzelne Extremereignisse können nun noch mit dem „TSEZoomView“ Wizard inspiziert werden:
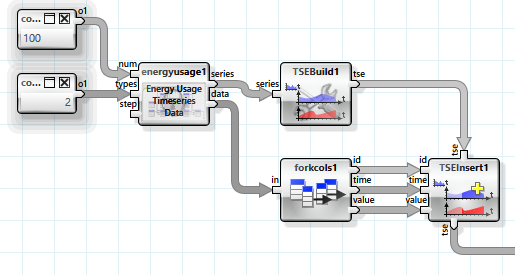 Alle Analysen in diesem Beispiel wurden auf einem Zeitreihen Objekt ausgeführt. Die einfachste Art, ein derartiges Objekt lokal zu erzeugen, besteht darin die einzelnen Datenströme von Messwerten mit einem einfachen Datenmodell zu spezifizieren. Die „TestDataGenerator“ Bibliothek verfügt über einen Operator, der Testdaten für Zeitreihen erstellen kann.
Alle Analysen in diesem Beispiel wurden auf einem Zeitreihen Objekt ausgeführt. Die einfachste Art, ein derartiges Objekt lokal zu erzeugen, besteht darin die einzelnen Datenströme von Messwerten mit einem einfachen Datenmodell zu spezifizieren. Die „TestDataGenerator“ Bibliothek verfügt über einen Operator, der Testdaten für Zeitreihen erstellen kann.
Über den „series“ Eingang des „TESBuild“ Operator werden die einzelnen Messreihen spezifiziert.
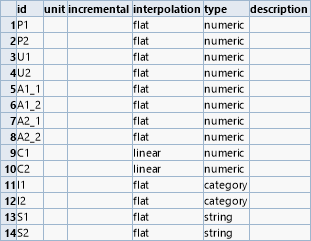
Jede Zeile deklariert eine Messreihe, wobei die einzelnen Spalten folgende Bedeutung haben:
- id
- Namen der Reihe, unter der sie später angesprochen werden kann
- unit
- Optionale Einheit der Messwerte
- incremental
- Logischer Wert, der angibt ob der Messwert stetig steigt
- interpolation
- Interpolationsmodus für numerische Daten
- type
- Typ der Datenwerte, Zahl, Kategorie oder Zeichenkette
- description
- Optionale Beschreibung
Wird ein Zeitreihen Objekt im Datenfluss inspiziert, so wird folgende Zusammenfassung angezeigt:
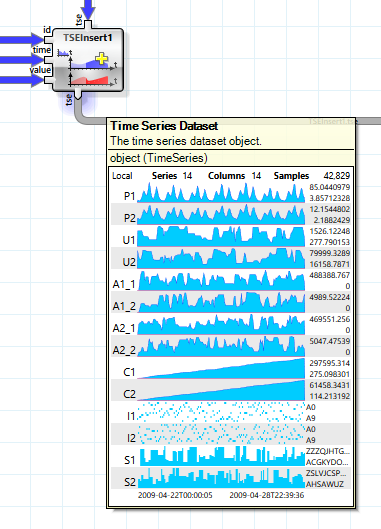
In der obersten Zeile wird der Speicherort (hier „Local“), die Zahl der Messreihen, sowie aktuell ausgewählten Spalten und die Gesamtzahl der Messwerte angezeigt. Zudem wird eine Auswahl der Messreihen in einfacher graphischer Form dargestellt. In der untersten Zeile werden zudem der Start- und der Endzeitpunkt angezeigt.
Alternativ kann ein Zeitreihenobjekt auch auf einem ARES Server erzeugt und bearbeitet werden. Alle Zeitreihenoperationen finden dann ebenfalls auf diesem Server statt, so dass nur ein geringer Anteil der Daten bei Anfragen übertragen werden müssen.
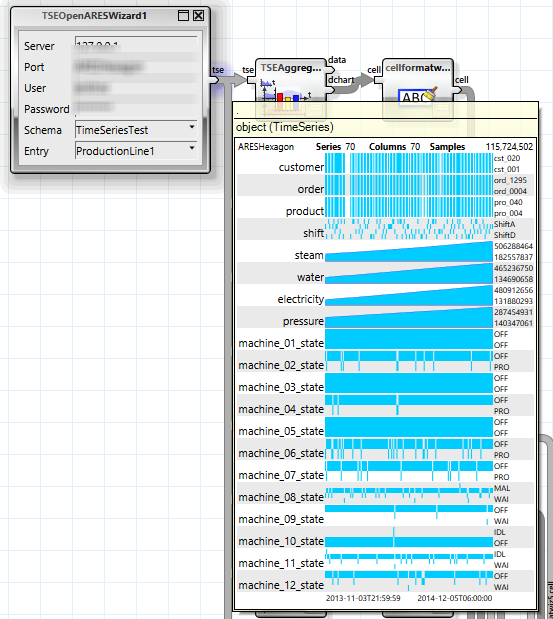
Die Speicherung auf einem ARES Server ist besonders nützlich, wenn die Daten kontinuierlich aus einem Produktivsystem um neue Messwerte ergänzt werden. Dies geschieht z.B. über ein Dämon FlowSheet auf einem Kollaborationsserver.
Neben der Verwendung zur Ad-Hoc Analyse können Zeitreihen Objekte auch für Dashboards (z.B. mit dem ANKHOR AHTTP Server) oder für automatisierte Reports eingesetzt werden. Eine weitere Anwendung ergibt sich aus dem Einsatz als http basierte Middleware in einem integrierten Reporting-System.
Hinweis:
alle in diesem Lösungsbeispiel gezeigten Diagramme wurde mit dem Time Series Analytics Paket erzeugt und nicht nachbearbeitet.